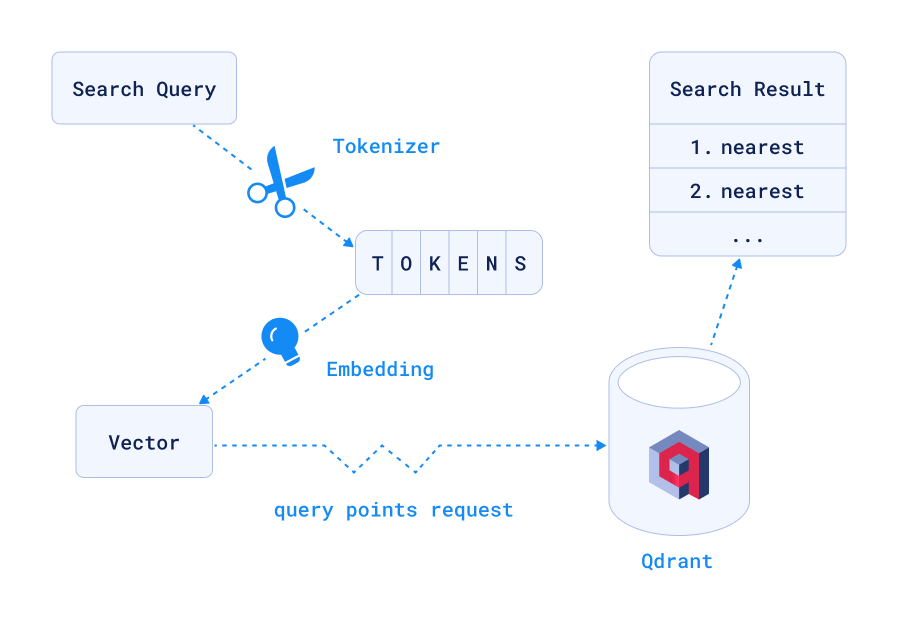
Vector Databases
AI systems are incredible—until you hit a data retrieval bottleneck. You’d need to search through millions of high-dimensional vectors, fast.
Vector databases are built specifically for similarity search, allowing AI apps to find the most relevant data points in milliseconds. And after trying several options, Qdrant became my go-to choice. It’s open-source and blazingly fast.
If you’re working on recommendation systems or a chatbot memory, Qdrant might be the missing piece in your stack.
1️. Qdrant for Recommendation System
Sometimes you may be thinking why Netflix keeps pushing that one show you swore you’d never watch? That’s vector similarity search in action.
How it works:
- Convert users and items into vector embeddings.
- Store those embeddings in Qdrant.
- Query for similar vectors to get recommendations.
Example: Movie Recommendation System
from qdrant_client import QdrantClient
import numpy as np
client = QdrantClient("localhost", port=6333)
client.upload_collection("movies", vectors=np.random.rand(100, 512).tolist())
query_vector = np.random.rand(512).tolist()
response = client.search("movies", query_vector=query_vector, limit=5)
print(response)
Boom! Now you can fetch movie recommendations faster than you can Google “best sci-fi movies.”
2️. Find Similar Images
Scenario: You upload a photo of your favorite sneakers, and an app instantly finds similar ones. That’s Qdrant working behind the scenes.
How it works:
- Convert images into feature vectors (CLIP, ResNet, EfficientNet, etc.).
- Store vectors in Qdrant.
- Search for similar vectors when a user uploads an image.
Example: Image Search with Qdrant
from torchvision import models, transforms
from PIL import Image
import torch
model = models.resnet50(pretrained=True)
model = torch.nn.Sequential(*list(model.children())[:-1])
transform = transforms.Compose([transforms.Resize((224, 224)), transforms.ToTensor()])
image = Image.open("sneaker.jpg")
vector = model(transform(image).unsqueeze(0)).detach().numpy().flatten()
client.upload_collection("images", vectors=[vector.tolist()])
response = client.search("images", query_vector=vector.tolist(), limit=3)
print(response)
And just like that, Qdrant helps you build a reverse image search tool.
3️. Chatbot Memory
Problem: Most chatbots have the memory of a goldfish. Ask them something from five minutes ago, and they’ll act like they’ve never met you.
Solution: Store chat history as vector embeddings in Qdrant so your AI assistant actually remembers past conversations.
Example: Chatbot Memory Storage
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("all-MiniLM-L6-v2")
messages = ["Hello!", "Tell me about AI", "What is machine learning?"]
embeddings = model.encode(messages).tolist()
client.upload_collection("chat_memory", vectors=embeddings)
query = model.encode("Explain machine learning").tolist()
response = client.search("chat_memory", query_vector=query, limit=2)
print(response)
Now your chatbot won’t ghost you mid-conversation.
4️. Anomaly Detection
Problem: Detecting fraud, cybersecurity threats, or defects in manufacturing without sifting through thousands of data points manually.
Solution: Store normal behavior in Qdrant and detect outliers based on vector distances.
Example: Detecting Network Anomalies
import numpy as np
from sklearn.decomposition import PCA
normal_data = np.random.rand(1000, 300)
anomalous_data = np.random.rand(1, 300) * 5
pca = PCA(n_components=50)
normal_vectors = pca.fit_transform(normal_data)
anomalous_vector = pca.transform(anomalous_data)
client.upload_collection("network_traffic", vectors=normal_vectors.tolist())
response = client.search("network_traffic", query_vector=anomalous_vector.tolist(), limit=5)
anomaly_score = sum(r['score'] for r in response) / len(response)
print("Anomaly Score:", anomaly_score)
Higher score = possible anomaly. Now, you can automate fraud detection like a pro.
Why It Stands Out?
- Real-time Search – Lightning-fast vector search, even with millions of embeddings.
- Scalability – Handles billions of vectors with distributed storage.
- Filter-Aware Search – Lets you query with metadata (e.g., “find similar movies from 2023”).
- Easy Integration – Works with Python, REST API, gRPC, and supports various embedding models.
Try it out, here: Qdrant Docs.